理想的索引 索引与排序
理想的索引
如何选择索引
1 查询频繁 2 区分度高 3 长度小 (占用内存少)4 尽可能覆盖常用查询字段
列如:
区分度:100万用户,性别基本上男、女各50万 区分度低
索引长度直接影响索引文件的大小,影响增删改的速度,并间接影响查询速度(占用内存多)
针对列中的值,从左往右截取部分来建立索引
1 截取的越短,重复度越高,区分度越小,索引效果越不好。
2 截取的越长,重复度越低,区分度越高,索引效果越好,但带来的影响越大,增删改慢并且影响查询速度。
所以我们要在 区分度 + 长度 两者取一个平衡。
1 截取不同长度并测试其区分度。
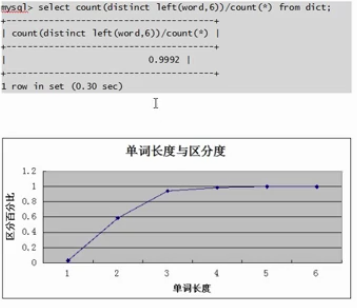
对于一般的系统应用,区分度能够达到0.1索引的性能就可以接受 (一行索引对应十条数据)
2 对于左前缀不易区分的列,建立索引技巧
左前缀不易区分比如网址都是以(http://www)开头
列的前11个字符都是一样的不易区分有以下两种方法:
(1) 把列内容倒过来存储并建立索引
moc.udiab.www//:ptth
这样左前缀区分大
(2) 伪hash索引效果
同样存储url hash列
|
|
函数crc32(url)计算URL列存入urlcrc列
查询时:select * from t10 where urlcrc = crc32(‘http://www.baidu.com‘)
3 多列索引
多列索引的考虑因素列的查询频率,列的区分度注意一定要结合实际业务场景
以商城为例 goods表中的cat_id(栏目),brand_id(品牌)做多列索引
从计算数据得出区分度Brand_id区分度更高
但是从商城实际业务看,顾客一般先选大分类->小分类->品牌
最终选择(1)index(cat_id,brand_id), (2)index(cat_id,shop_price)来建立索引(建立两个复合索引)1 ,2两个索引称为冗余索引
甚至可以再加(3)index(cat_id,brand_id,shop_price)1 3放在一起就是重复索引
但(3)中的前2列和(1)中的前两列一样,再去掉(1)
最终建立:Index(cat_id,shop_price)和index(cat_id,brand_id,shop_price)这两个复合索引
索引与排序
排序可能发生2种情况
1 对于索引覆盖直接在索引上查询,就是有序的,using index
在innodb引擎中沿着索引字段排序查询,也是自然有序的,而对于mysisam引擎,如果按某索引字段排序如id 但取出的字段中有未索引字段,myisam做法不是索引->回行,索引->回行。而是先取出所有行,再进行排序。
2 先取出数据,形成临时表做filesort文件排序,但文件可能在磁盘上,也可能在内存中
我们的争取的目标…..取出来的数据本身就是有序的,利用索引来排序
比如表:goods商品(cat_id,shop_price)组成联合索引
Where cat_id=N order by shop_price 可以利用索引排序
Select goods_id,cat_id,shop_price from goods order by shop_price,
//using where 按照shop_price索引取的结果,本身就是有序的
Select goods_id,cat_id,shop_price from goods order by click_count
//using filesort 用到文件排序即取出的结果再次排序