Myisam与innodb引擎聚簇非聚簇
Myisam与innodb引擎,索引文件的异同
Myisam索引与数据关系是,索引与数据分离,每个索引都指向在磁盘上的位置,也就是说主索引和次索引都指向物理行(磁盘位置) 我们称之为非聚簇索引。
Innodb索引与数据的关系,直接在索引树中,直接存储行的数据,次索引指向对主键的引用我们称之为聚簇索引。
如图所示Myisam与innodb引擎存储索引对比
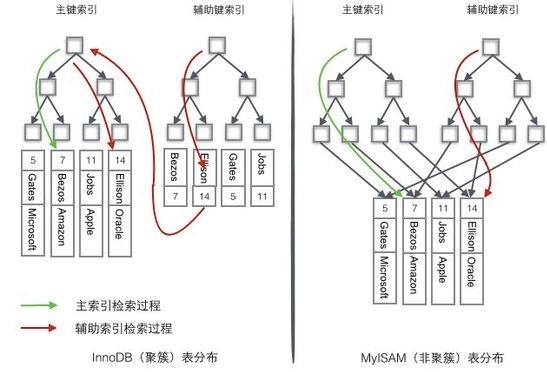
注意:innodb来说
1 主键索引即存储索引值,又在叶子中存储行的数据
2 如果没有主键(primary key)则会unique key做主键
3 如果没有unique key系统生成一个内部的rowid做主键
4 像innodb中,主键索引结构中即存储主键值又存储行数据这种结构称之为”聚簇索引”
聚簇索引
优势:根据主键查询条目比较少时,不用回行(数据就在主键节点下)
劣势:如果碰到不规则数据插入时,造成频繁的树上叶节点分裂
聚簇索引的页分裂过程
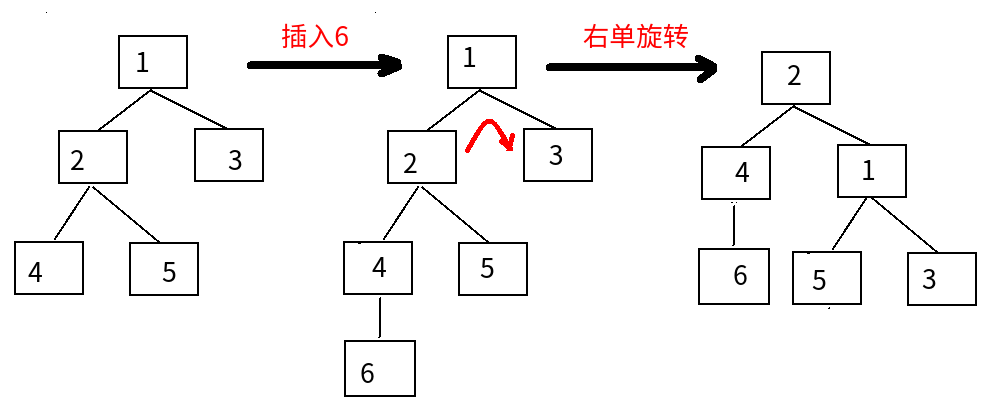
二叉平衡树插入数据会打破树的平衡,需要重新排列
二叉排序树的平衡旋转图例
1 LL:右单旋转
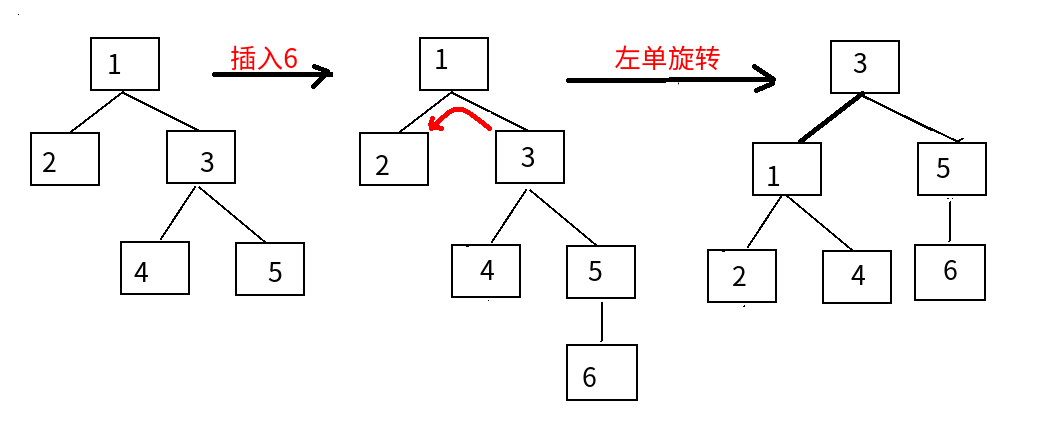
2 RR左单旋转
3 LR平衡旋转:先左后右
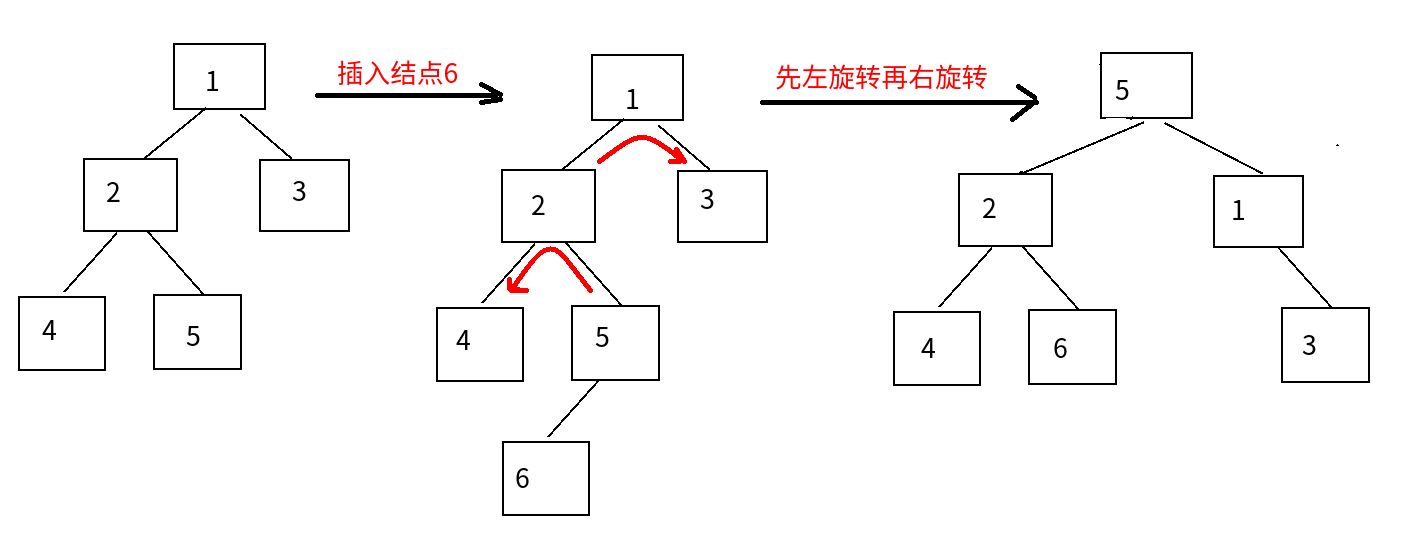
4 RL平衡旋转:先右后左
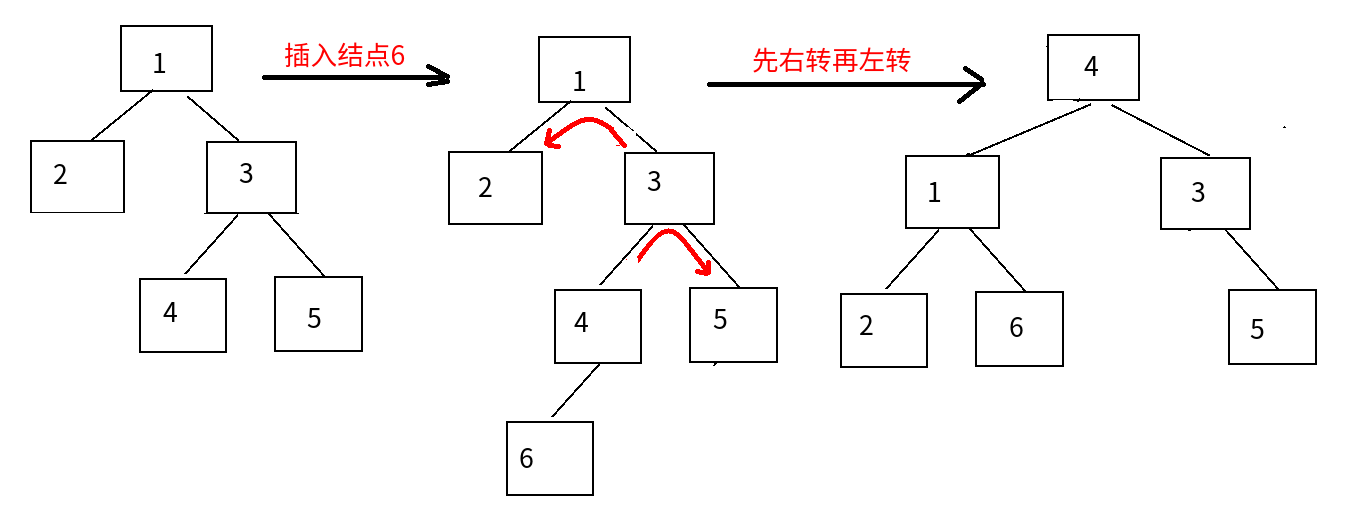
高性能索引策略
对于innodb而言因为节点下有数据文件,因此节点的分裂将会比较慢
对于innodb的主键尽量用整型,而且是递增的整型
如果是无规律的数据将会产生页的分裂,影响速度
索引覆盖
查询列要被所使用的索引覆盖。
索引覆盖是指 如果查询的列恰好是索引的一部分那么查询只需要在索引文件上进行不需要回行到磁盘进行找数据
这种查询速度非常快称之为‘索引覆盖’
不是所有类型的索引都可以成为覆盖索引。覆盖索引必须要存储索引的列,而哈希索引、空间索引和全文索引等都不存储索引列的值,所以MySQL只能使用B-Tree索引做覆盖索引
优点:
1.索引条目通常远小于数据行大小,只需要读取索引,则mysql会极大地减少数据访问量。
2.因为索引是按照列值顺序存储的,所以对于IO密集的范围查找会比随机从磁盘读取每一行数据的IO少很多。
3.一些存储引擎如myisam在内存中只缓存索引,数据则依赖于操作系统来缓存,因此要访问数据需要一次系统调用
4.innodb的聚簇索引,覆盖索引对innodb表特别有用。(innodb的二级索引在叶子节点中保存了行的主键值,所以如果二级主键能够覆盖查询,则可以避免对主键索引的二次查询)
几种优化场景:
1.无WHERE条件的查询优化:
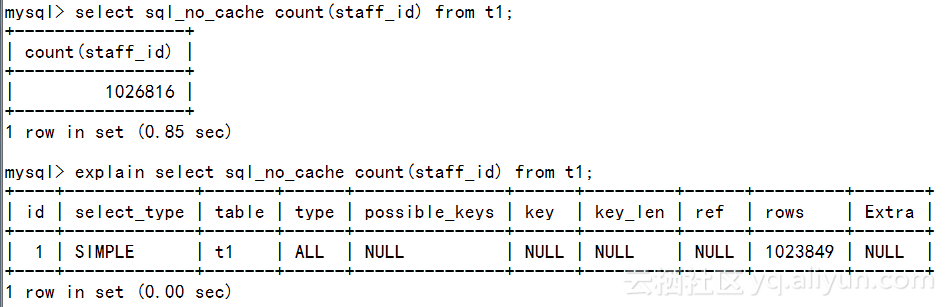
执行计划中,type 为ALL,表示进行了全表扫描
如何改进?优化措施很简单,就是对这个查询列建立索引。如下,
再看一下执行计划
possible_key: NULL,说明没有WHERE条件时查询优化器无法通过索引检索数据,这里使用了索引的另外一个优点,即从索引中获取数据,减少了读取的数据块的数量。 无where条件的查询,可以通过索引来实现索引覆盖查询,但前提条件是,查询返回的字段数足够少,更不用说select *之类的了。毕竟,建立key length过长的索引,始终不是一件好事情。
经过再次查询时间缩短0.13sec
2、二次检索优化
|
|
执行计划
Extra:Using index condition 表示使用的索引方式为二级检索,即79999个书签值被用来进行回表查询。可想而知,还是会有一定的性能消耗的
尝试针对这个SQL建立联合索引,如下:
执行计划:
Extra:Using index 表示没有会标查询的过程,实现了索引覆盖